为什么系统被程序员“删库跑路”,就很难恢复,背后的真实原因?
2020-02-29 23:09:00 来源: 评论:0 点击:
摘要:在IT行业,程序员们经常相互开玩笑说,大不了我们“删库跑路”,显然这只是一句IT界的玩笑话,基本上也没有人会这样干。然而,近期微盟就遭遇内部员工“删库跑路”事件,服务出现故障,大面积服务集群无相应,系统很难再短时间内恢复。那么,为什么
摘要:在IT行业,程序员们经常相互开玩笑说,大不了我们“删库跑路”,显然这只是一句IT界的玩笑话,基本上也没有人会这样干。然而,近期微盟就遭遇内部员工“删库跑路”事件,服务出现故障,大面积服务集群无相应,系统很难再短时间内恢复。那么,为什么系统被程序员“删库跑路”,就很难恢复,背后的真实原因?

在IT行业圈中,“删库跑路”往往是IT圈内人相互调侃的一个段子,而这也正是因为删库这一错误实在太低级,在高学历、高技术能力的IT行业人员中才能成为一个梗。毕竟这一行为直接违反了我国《刑法》的第286条,也就是破坏计算机信息系统罪。所以大家都只当玩笑话,没人敢在系统中键入“rm -rf / ”这一命令。
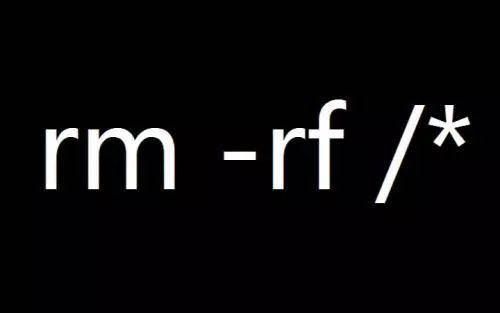
然而,在2月25日,微盟官方发布《自愿公告SaaS业务生产环境和数据遭到破坏》,称2月23日晚7点,收到系统监控报警,服务出现故障,大面积服务集群无相应。微盟表示,本次SaaS业务数据系遭一员工“人为破坏”,而在SaaS 生产环境和数据遭到破坏后,微盟当前已暂时无法向客户提供 SaaS 产品服务。
其实,在IT历史上此类事件其实不在少数,2015年5月28日中午11时左右,携程官网和APP同时崩溃,一时之间,携程数据库被物理删除的说法在网上盛传,直到深夜23:29,携程才逐渐恢复。第二天,携程发布官方解释,称是由于运维员工的错误操作,删除了生产服务器上的执行代码导致,最终的详细报告官方并没有公布。

另一个著名的事件是2017年2月,GitLab数据库也出现了误删,当时由于遭受DDoS攻击造成staging数据库(db2.staging)落后生产数据库(db1.cluster)4GB的数据,并且staging数据库由于PostgreSQL的问题处于hang状态,在试图修复这个问题的过程中造成了删错库的误操作,最终造成很多项目代码不同程度的丢失。
IT圈子外的人可能很难理解,感觉不就是重装一下系统嘛,数据库不是都应该有备份嘛,直接恢复一下不就行了嘛,其实事情远远要比你想的复杂得多。那么,为什么系统被程序员“删库跑路”,就很难恢复,背后的真实原因?
很多时候,人常常会有一个认知上的偏差,对于一个自己没有切身参与过的领域,我们会不自觉地对难度产生错误的判断。这种所谓的迷之自信,是很难克服的。

熟悉现代软件架构和运维的同学一定知道,现在软件的架构以及部署是极其复杂的,尤其在微服务大行其道的当下,每个微服务本身就是一个集群,微服务和微服务之间还有各种依赖关系,同时每个微服务都有可能会和数据库打交道,光理清楚这些服务之间的依赖和配置就够大家受的了,几乎涉及整体架构的全局梳理,比重新开发一套系统还麻烦。这才是系统被程序员“删库跑路”后,就很难恢复的真正原因。你觉得呢?
相关热词搜索:
上一篇:为什么说MP3音乐播放器并没有被手机淘汰,究竟怎么回事?
下一篇:为什么5G手机用4G网络,却比4G手机快,究竟怎么回事?
分享到:
 收藏
收藏
收藏
评论排行
- ·手机“双卡双待”,卡一...(3)